前面兩天,我們對需要用的欄位做了特徵工程、缺失值的補充、值得轉換等
我們已經將資料前處理做得差不多了,接著在做一些動作就可以拿下去train了
將DataFram轉成ndarray:
選擇要使用的欄位透過values屬性獲得ndarray的資料型態
透過布林索引及欄位的選擇分成train_x、train_y、test_x
雖然我們前面有處理過Fare這個欄位,但我發現加入Fare這個欄位滿影響訓練結果的,我猜~可能是因為我沒對此欄位觀察得很好吧! 反正我就是不要用此欄位
正規化
正規化以利訓練,我使用了MinMaxScaler這個方法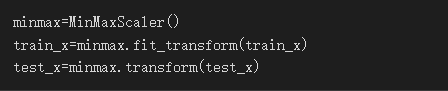
轉為tensor
一定要記得轉成tensor,不然是不能train的
分成train_set、validate_set
比例我設成train_set佔8成,validate_set佔2成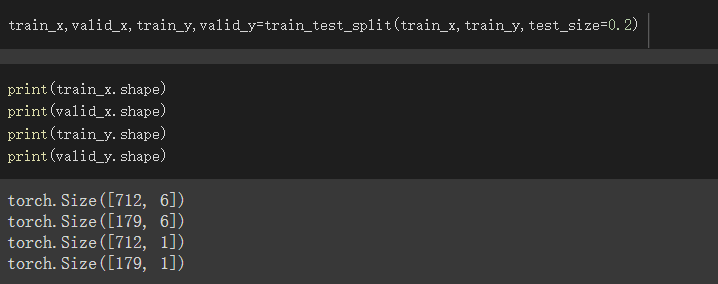
Dataset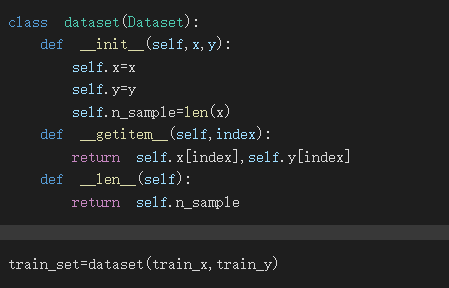
DataLoader
batch_size我設成100,shuffle記得設成True,因為這要拿下去train
model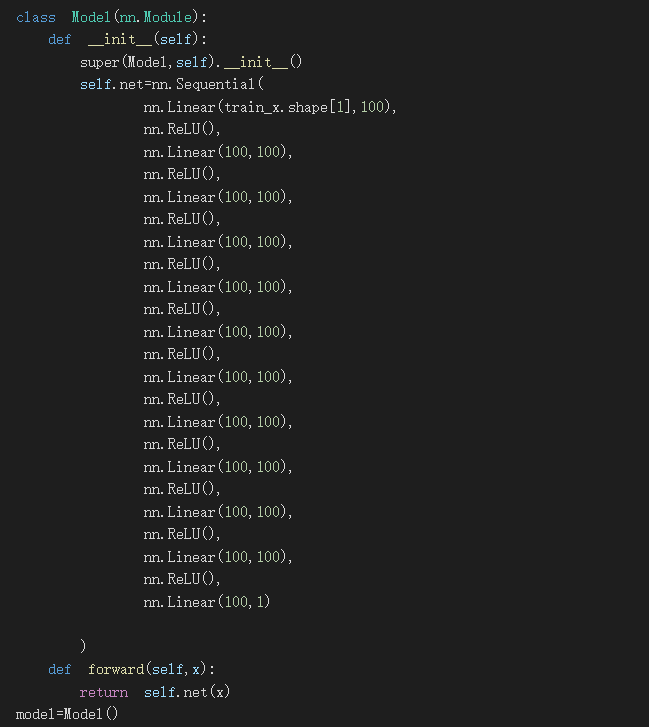
critirion、optimizer、epoch、n_batch
設置n_batch=len(train_loader)是為了好看資料的訓練過程
其他的以前都有說過就不解釋了
設定best_acc變數
我設定了一個變數為best_acc,並指派為0
此變數是為了之後訓練來記錄最好的model並做儲存
等一下看訓練過程就能知道實際我是怎麼操作的
開始訓練model
這部分我會分成三個部分來講解
我分別用了白色框、黃色框、紅色框分組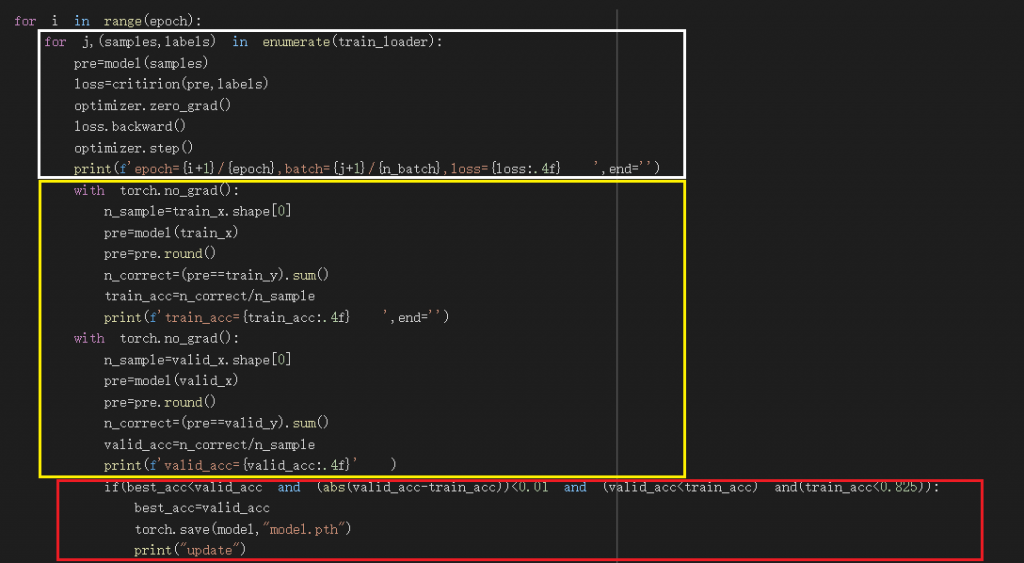
白色框:
白色框為訓練的過程及程式碼,會print第幾個epoch、第幾個batch、loss的數值
黃色框:
黃色框有兩個with torch.no_grad():
上面的部分為將training用的資料放入現在的模型並print出正確率
下面的部分為將validate用的資料放入現在的模型並print出正確率
pre.round()會將數值做四捨五入,因為我們要預測的數值不是1就是0來判斷有無生存
n_correct=(pre==train_y).sum()會算出答案正確的個數
紅色框:
這裡設定了我儲存model的條件,這裡就有用到我前面設定的best_acc這個變數
best_acc用來儲存最好的valid_acc
valid_acc黃色框裡所算出的驗證集正確率
train_acc黃色框裡所算出的訓練集正確率
解釋我if判斷式裡都放了什麼
best_acc < valid_acc 成立時,表示新的驗證集正確率比best_acc還高
abs(valid_acc-train_acc) < 0.01 成立時,表示驗證集正確率與訓練集正確率差距小於0.01,這是一個避免過度擬合的設定
valid_acc < train_acc 成立時,表示驗證集正確率小於訓練集正確率,因為這場來說,在訓練時訓練集正確率不會比驗證集正確率還高,如果訓練集正確率大於驗證集正確率,只是model剛好符合驗證集的資料狀況
train_acc < 0.825 ,此項是避免讓model過度擬合的設定,因為在我觀察訓練的過程,大部分驗證集的正確率到後來都位於0.8~0.825之間,幾乎無法再有提升,很少有大於0.83的正確率,表示如過大於0.83大概都只是model剛好符合驗證集的資料狀況
train_acc < 0.825 ,abs(valid_acc-train_acc) < 0.01,此兩個判別的配合使我們能儲存到一個不會過度擬合、正確率又高的model
載入model並輸出答案
載入模型
算出答案並製作成DataFrame
輸出CSV檔
pre=pre.view(-1).numpy().astype(np.int)這段程式碼我解釋一下
原本model輸出的pre為二維,透過view方法轉成1維
numpy將tensor型態轉乘ndarray,astype改變資料型態
之後就可以交上kaggle囉~
繳交結果
IT_submission 為DNN的訓練結果(就是本文章的結果)
SVM_submission 為SVM的訓練結果(後面文章會寫)
KNN_submission 為KNN的訓練結果 (後面文章會寫)
Kmeans_submission 為Kmeans的訓練結果(後面文章會寫)
此全部都用相同的資料前處理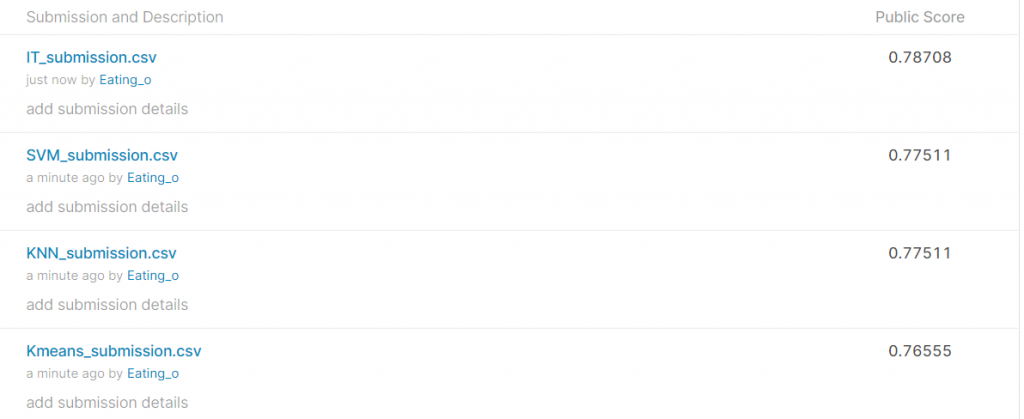
送上整個資料處理及訓練過程
https://colab.research.google.com/drive/1l--rkdk0sCxrEAGyETSxFCMrJmS147tX?usp=sharing

